前言
整整一篇文章直接搬运而来的,强烈建议直接查看原文 ,对于多维数据的展示技巧和方法,说的相当的透彻,这篇文章收藏于2020年初,绘图技术的艺术品;下面就直接给出原文的内容,经过谷歌翻译后抄录如下。 另外数据集合可点击链接 下载;
介绍
描述性分析是与数据科学项目甚至特定研究相关的任何分析生命周期的核心组成部分之一。数据聚合、汇总和可视化是支持该数据分析领域的一些主要支柱。从传统商业智能时代到人工智能、数据可视化时代它是一种强大的工具,由于它能够有效地提取正确的信息、清晰、轻松地理解和解释结果,因此已被各组织广泛采用。然而,处理通常具有两个以上属性的多维数据集开始引起问题,因为数据分析和通信媒介通常仅限于二维。在本文中,将探索一些在多个维度(从一维到六维)可视化数据的有效策略。
动机
“一图胜千言”
这是我们都熟悉的非常流行的英语习语,应该为我们理解和利用数据可视化作为分析中的有效工具提供足够的灵感和动力。永远记住“有效的数据可视化既是一门艺术,也是一门科学”。开始之前,我还想提一下下面的引言,它确实相关,并且强调了数据可视化的必要性。
“一幅画的最大价值在于它迫使我们注意到我们从未想到过的东西。” — 约翰·图基
快速回顾一下可视化
我假设普通读者了解用于绘制和可视化数据的基本图形和图表,因此我不会进行详细解释,但我们将在此处的实践实验中涵盖其中的大部分内容。正如著名可视化先驱和统计学家Edward Tufte所提到的,数据可视化应该在数据之上利用,以“清晰、精确和高效”的方式传达模式和见解。
结构化数据通常由行表示的数据观察和列表示的特征或数据属性组成。每一列也可以称为数据集的一个特定维度。最常见的数据类型包括连续数值数据和离散分类数据。因此,任何数据可视化基本上都会以一种易于理解的视觉效果(如散点图、直方图、箱线图等)来描述一个或多个数据属性。我将介绍单变量(一维)和多变量(多维)数据可视化策略。我们将在这里使用 Python 机器学习生态系统,我们建议您查看数据分析和可视化框架,包括pandas、matplotlib、seaborn和plotlybokeh。除此之外,如果您有兴趣用数据制作美观且有意义的可视化,那么了解D3.js 也是必须的。有兴趣的读者建议阅读爱德华·塔夫特(Edward Tufte)的《定量信息的视觉显示》。
空谈是廉价的,向我展示可视化(和代码)!
让我们开始吧,而不是我喋喋不休地谈论理论和概念。我们将使用UCI 机器学习存储库中提供的葡萄酒质量数据集。该数据实际上由两个数据集组成,描述了葡萄牙“Vinho Verde”葡萄酒的红色和白色变体的各种属性。本文中的所有分析都可以在我的GitHub 存储库中作为Jupyter Notebook获取,供那些渴望亲自尝试的人使用!
我们将首先加载以下必要的依赖项以进行分析。
import pandas as pdimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dimport matplotlib as mplimport numpy as npimport seaborn as sns%matplotlib inline
我们将主要使用matplotlib 和seaborn 作为我们的可视化框架,但您可以自由地检查并尝试与您选择的任何其他框架进行相同的操作。我们来看看经过一些基本数据预处理步骤后的数据。
white_wine = pd.read_csv('winequality-white.csv' , sep =';' ) red_wine = pd.read_csv('winequality-red.csv' , sep =';' ) red_wine['wine_type' ] = 'red' white_wine['wine_type' ] = 'white' red_wine['quality_label' ] = red_wine['quality' ].apply(lambda value: 'low' if value <= 5 else 'medium' if value <= 7 else 'high' ) red_wine['quality_label' ] = pd.Categorical(red_wine['quality_label' ], categories=['low' , 'medium' , 'high' ]) white_wine['quality_label' ] = white_wine['quality' ].apply(lambda value: 'low' if value <= 5 else 'medium' if value <= 7 else 'high' ) white_wine['quality_label' ] = pd.Categorical(white_wine['quality_label' ], categories=['low' , 'medium' , 'high' ]) wines = pd.concat([red_wine, white_wine]) wines = wines.sample(frac =1, random_state =42).reset_index(drop=True)
我们通过合并与红葡萄酒和白葡萄酒样品相关的数据集来创建单个数据框葡萄酒。我们还quality_label 根据quality葡萄酒样品的属性创建了一个新的分类变量。现在让我们看一下数据。
很明显,我们有葡萄酒样品的几个数字和分类属性。每个观察结果都属于红葡萄酒或白葡萄酒样品,属性是通过物理化学测试测量和获得的特定属性或特性。如果你想了解每个属性的详细解释,你可以查看Jupyter Notebook ,但名称非常不言自明。让我们对其中一些感兴趣的属性进行快速的基本描述性汇总统计。
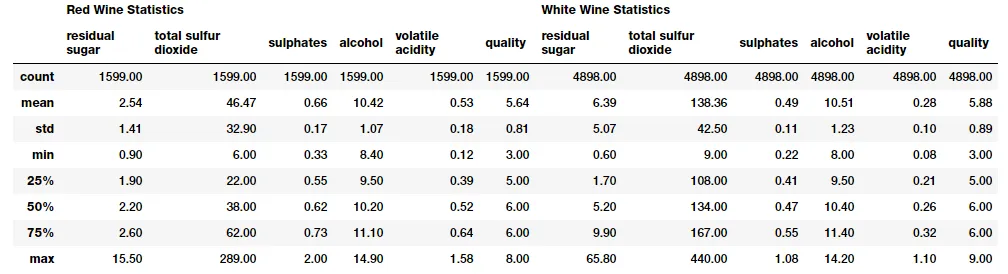
subset_attributes = ['residual sugar' , 'total sulfur dioxide' , 'sulphates' , 'alcohol' , 'volatile acidity' , 'quality' ] rs = round(red_wine[subset_attributes].describe(),2 ) ws = round(white_wine[subset_attributes].describe(),2 ) pd.concat([rs, ws], axis=1 , keys=['Red Wine Statistics' , 'White Wine Statistics' ])
对比和比较不同类型葡萄酒样品的这些统计测量值非常容易。请注意某些属性的明显差异。稍后我们将在一些可视化中强调这些内容。
单变量分析
单变量分析基本上是数据分析或可视化的最简单形式,我们只关心分析一个数据属性或变量并将其可视化(一维)。
一维 (1-D) 可视化数据
可视化所有数值数据及其分布的最快、最有效的方法之一是利用直方图 pandas
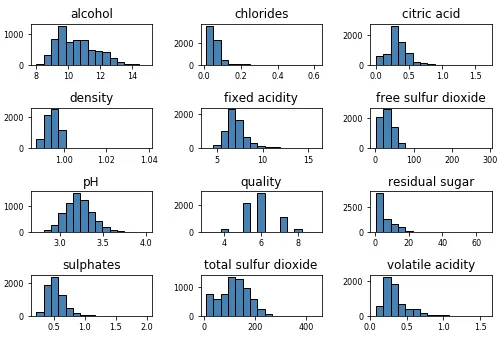
wines.hist(bins =15, color ='steelblue' , edgecolor ='black' , linewidth =1.0, xlabelsize =8, ylabelsize =8, grid =False ) plt.tight_layout(rect=(0, 0, 1.2, 1.2))
上图很好地了解任何属性的基本数据分布。 让我们深入了解连续数字属性之一的可视化。本质上,直方图或密度图可以很好地理解该属性的数据分布情况。
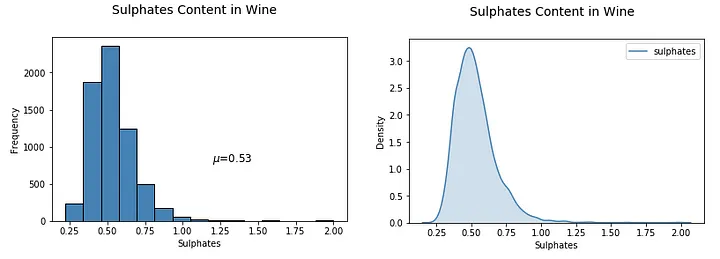
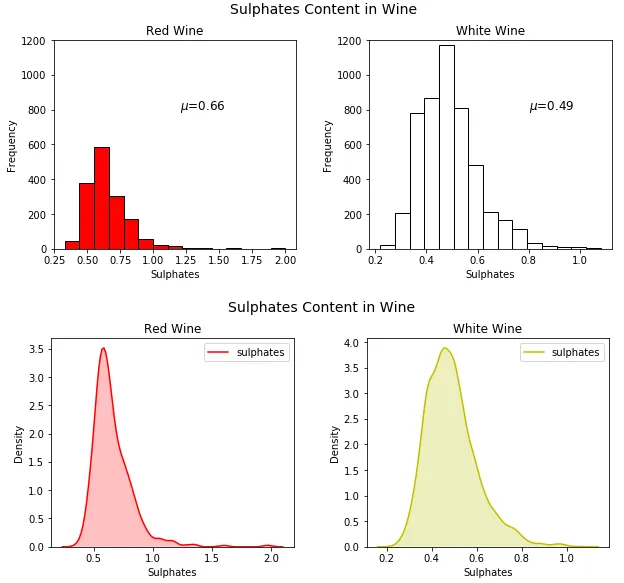
fig = plt.figure(figsize = (6,4)) title = fig.suptitle("Sulphates Content in Wine" , fontsize =14) fig.subplots_adjust(top =0.85, wspace =0.3) ax = fig.add_subplot(1,1, 1) ax.set_xlabel("Sulphates" ) ax.set_ylabel("Frequency" ) ax.text(1.2, 800, r'$\mu$=' +str(round(wines['sulphates' ].mean(),2)), fontsize =12) freq, bins, patches = ax.hist(wines['sulphates' ], color ='steelblue' , bins =15, edgecolor ='black' , linewidth =1) fig = plt.figure(figsize = (6, 4)) title = fig.suptitle("Sulphates Content in Wine" , fontsize =14) fig.subplots_adjust(top =0.85, wspace =0.3) ax1 = fig.add_subplot(1,1, 1) ax1.set_xlabel("Sulphates" ) ax1.set_ylabel("Frequency" ) sns.kdeplot(wines['sulphates' ], ax =ax1, shade =True , color ='steelblue' )
从上图可以明显看出,葡萄酒的分布存在明显的右偏sulphates。可视化离散的分类数据属性略有不同,条形图 是实现这一点的最有效方法之一。您也可以使用饼图,但一般来说尽量避免使用它们,特别是当不同类别的数量超过三个时。
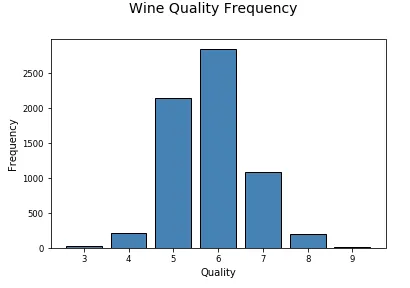
fig = plt.figure(figsize = (6, 4)) title = fig.suptitle("Wine Quality Frequency" , fontsize =14) fig.subplots_adjust(top =0.85, wspace =0.3) ax = fig.add_subplot(1,1, 1) ax.set_xlabel("Quality" ) ax.set_ylabel("Frequency" ) w_q = wines['quality' ].value_counts() w_q = (list(w_q.index), list(w_q.values)) ax.tick_params(axis ='both' , which ='major' , labelsize =8.5) bar = ax.bar(w_q[0], w_q[1], color ='steelblue' , edgecolor ='black' , linewidth =1)
现在让我们继续研究更高维的数据。
多元分析
多变量分析是乐趣和复杂性的开始。在这里,我们分析多个数据维度或属性(2个或更多)。多变量分析不仅涉及检查分布,还涉及这些属性之间的潜在关系、模式和相关性。如有必要,您还可以根据要解决的问题利用推论统计和假设检验来检查不同属性、组等的统计显着性。
二维(2-D)数据可视化
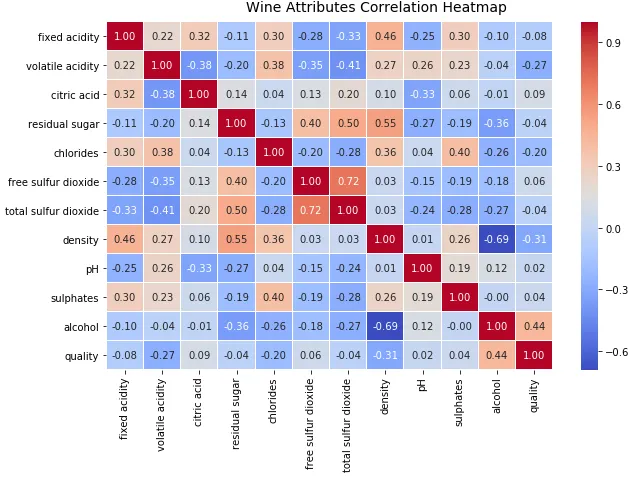
检查不同数据属性之间的潜在关系或相关性的最佳方法之一是利用成对相关矩阵 并将其描述为热图。
f, ax = plt.subplots(figsize=(10, 6)) corr = wines.corr() hm = sns.heatmap(round(corr,2), annot =True , ax =ax, cmap ="coolwarm" ,fmt='.2f', linewidths =.05) f.subplots_adjust(top =0.93) t= f.suptitle('Wine Attributes Correlation Heatmap' , fontsize =14)
热图中的梯度根据相关性的强度而变化,您可以清楚地看到很容易发现彼此之间具有强相关性的潜在属性。另一种可视化的方法是在感兴趣的属性之间使用成对散点图。
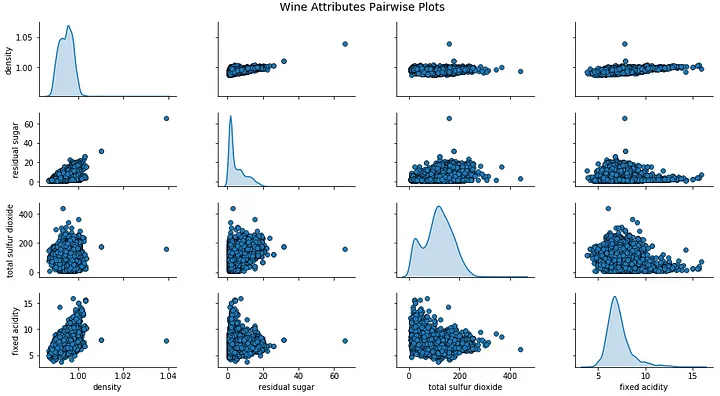
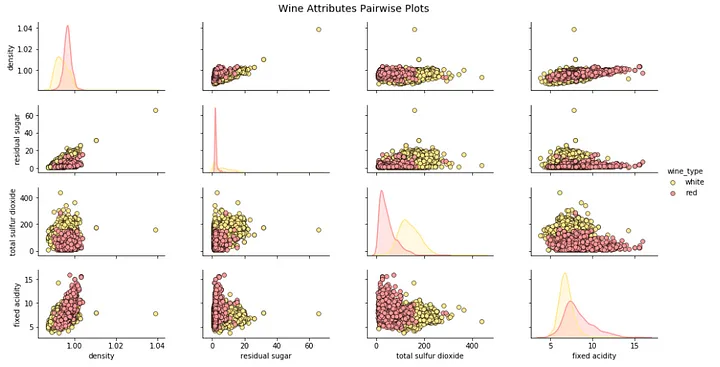
cols = ['density' , 'residual sugar' , 'total sulfur dioxide' , 'fixed acidity' ] pp = sns.pairplot(wines[cols], size =1.8, aspect =1.8, plot_kws =dict(edgecolor="k", linewidth =0.5), diag_kind ="kde" , diag_kws =dict(shade=True)) fig = pp.fig fig.subplots_adjust(top =0.93, wspace =0.3) t = fig.suptitle('Wine Attributes Pairwise Plots' , fontsize =14)
根据上图,您可以看到散点图也是观察数据属性的二维潜在关系或模式的好方法。
关于成对散点图需要注意的重要一点是这些图实际上是对称的。任何一对属性的散点图(X, Y)看起来与相同属性不同只是(Y, X)因为垂直和水平尺度不同。它不包含任何新信息。
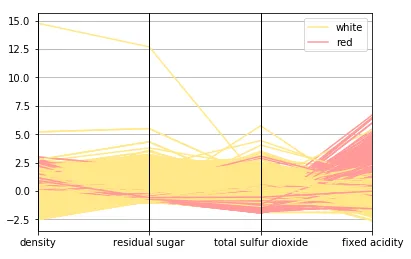
将多个属性的多元数据一起可视化的另一种方法是使用平行坐标。
# Scaling attribute values to avoid few outiers cols = ['density' , 'residual sugar' , 'total sulfur dioxide' , 'fixed acidity' ] subset_df = wines[cols] from sklearn.preprocessing import StandardScalerss = StandardScaler() scaled_df = ss.fit_transform(subset_df) scaled_df = pd.DataFrame(scaled_df, columns =cols) final_df = pd.concat([scaled_df, wines['wine_type' ]], axis=1 ) final_df.head() # plot parallel coordinates from pandas.plotting import parallel_coordinatespc = parallel_coordinates(final_df, 'wine_type' , color=('#FFE888' , '#FF9999' ))
基本上,在如上所述的可视化中,点表示为连接的线段。每条垂直线代表一个数据属性。跨越所有属性的一组完整的连接线段代表一个数据点。因此,倾向于聚集的点会显得更靠近。只要看一下,我们就可以清楚地看到红葡萄酒比白葡萄酒密度略多一些。此外,白葡萄酒的和值高于红葡萄酒,红葡萄酒的值高于。查看我们之前导出的统计表中的统计数据来验证这个假设!
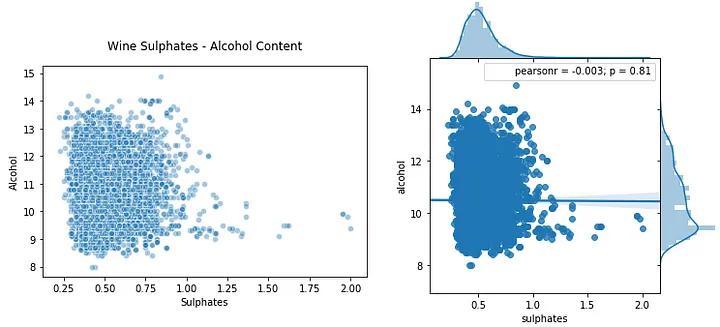
让我们看一下可视化两个连续的数字属性的一些方法。散点图和联合图尤其是检查模式和关系的好方法,而且还可以查看属性的单独分布。
plt.scatter(wines['sulphates' ], wines['alcohol' ], alpha =0.4, edgecolors ='w' ) plt.xlabel('Sulphates' ) plt.ylabel('Alcohol' ) plt.title('Wine Sulphates - Alcohol Content' ,y =1.05) jp = sns.jointplot(x ='sulphates' , y ='alcohol' , data =wines, kind ='reg' , space =0, size =5, ratio =4)
上图中左侧为散点图,右侧为联合图。正如我们提到的,您可以检查联合图中的相关性、关系以及个体分布。可视化两个离散的分类属性怎么样?一种方法是利用单独的图(子图)或方面作为分类维度之一。
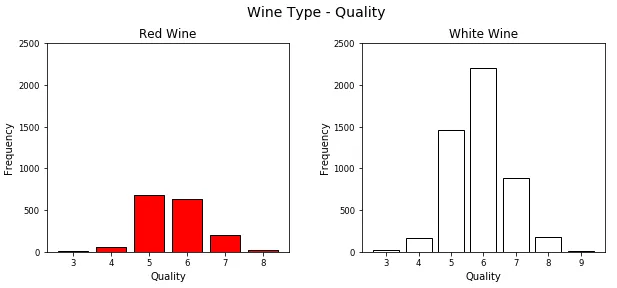
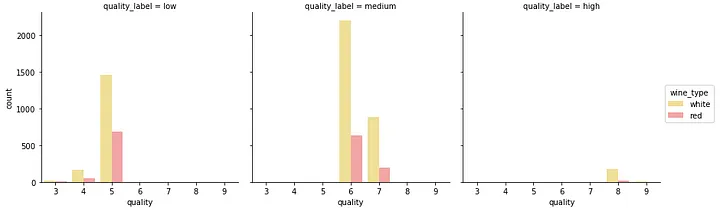
fig = plt.figure(figsize = (10, 4)) title = fig.suptitle("Wine Type - Quality" , fontsize =14) fig.subplots_adjust(top =0.85, wspace =0.3) ax1 = fig.add_subplot(1,2, 1) ax1.set_title("Red Wine" ) ax1.set_xlabel("Quality" ) ax1.set_ylabel("Frequency" ) rw_q = red_wine['quality' ].value_counts() rw_q = (list(rw_q.index), list(rw_q.values)) ax1.set_ylim([0, 2500]) ax1.tick_params(axis ='both' , which ='major' , labelsize =8.5) bar1 = ax1.bar(rw_q[0], rw_q[1], color ='red' , edgecolor ='black' , linewidth =1) ax2 = fig.add_subplot(1,2, 2) ax2.set_title("White Wine" ) ax2.set_xlabel("Quality" ) ax2.set_ylabel("Frequency" ) ww_q = white_wine['quality' ].value_counts() ww_q = (list(ww_q.index), list(ww_q.values)) ax2.set_ylim([0, 2500]) ax2.tick_params(axis ='both' , which ='major' , labelsize =8.5) bar2 = ax2.bar(ww_q[0], ww_q[1], color ='white' , edgecolor ='black' , linewidth =1)
正如您所看到的,虽然这是可视化分类数据的好方法,但利用它matplotlib 会导致编写大量代码。另一个好方法是对单个图中的不同属性使用堆叠条形图或多个条形图。我们可以 seaborn 轻松地利用这一点。
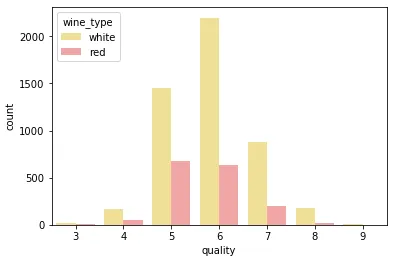
cp = sns.countplot(x ="quality" , hue ="wine_type" , data =wines, palette={"red" : "#FF9999" , "white" : "#FFE888" })
这绝对看起来更干净,您还可以从这个单一图中轻松有效地比较不同的类别。 让我们看一下二维混合属性的可视化(本质上是数字属性和分类属性)。一种方法是使用分面/子图以及通用直方图或密度图。
fig = plt.figure(figsize = (10,4)) title = fig.suptitle("Sulphates Content in Wine" , fontsize =14) fig.subplots_adjust(top =0.85, wspace =0.3) ax1 = fig.add_subplot(1,2, 1) ax1.set_title("Red Wine" ) ax1.set_xlabel("Sulphates" ) ax1.set_ylabel("Frequency" ) ax1.set_ylim([0, 1200]) ax1.text(1.2, 800, r'$\mu$=' +str(round(red_wine['sulphates' ].mean(),2)), fontsize =12) r_freq, r_bins, r_patches = ax1.hist(red_wine['sulphates' ], color ='red' , bins =15, edgecolor ='black' , linewidth =1) ax2 = fig.add_subplot(1,2, 2) ax2.set_title("White Wine" ) ax2.set_xlabel("Sulphates" ) ax2.set_ylabel("Frequency" ) ax2.set_ylim([0, 1200]) ax2.text(0.8, 800, r'$\mu$=' +str(round(white_wine['sulphates' ].mean(),2)), fontsize =12) w_freq, w_bins, w_patches = ax2.hist(white_wine['sulphates' ], color ='white' , bins =15, edgecolor ='black' , linewidth =1) fig = plt.figure(figsize = (10, 4)) title = fig.suptitle("Sulphates Content in Wine" , fontsize =14) fig.subplots_adjust(top =0.85, wspace =0.3) ax1 = fig.add_subplot(1,2, 1) ax1.set_title("Red Wine" ) ax1.set_xlabel("Sulphates" ) ax1.set_ylabel("Density" ) sns.kdeplot(red_wine['sulphates' ], ax =ax1, shade =True , color ='r' ) ax2 = fig.add_subplot(1,2, 2) ax2.set_title("White Wine" ) ax2.set_xlabel("Sulphates" ) ax2.set_ylabel("Density" ) sns.kdeplot(white_wine['sulphates' ], ax =ax2, shade =True , color ='y' )
虽然这很好,但我们再次拥有大量样板代码,我们可以通过利用这些样板代码来避免这些代码 seaborn ,甚至可以在一张图表中绘制图表。
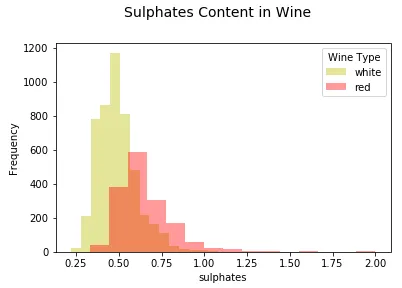
fig = plt.figure(figsize = (6, 4)) title = fig.suptitle("Sulphates Content in Wine" , fontsize =14) fig.subplots_adjust(top =0.85, wspace =0.3) ax = fig.add_subplot(1,1, 1) ax.set_xlabel("Sulphates" ) ax.set_ylabel("Frequency" ) g = sns.FacetGrid(wines, hue ='wine_type' , palette={"red" : "r" , "white" : "y" }) g.map(sns.distplot, 'sulphates' , kde =False , bins =15, ax =ax) ax.legend(title ='Wine Type' ) plt.close(2)
您可以看到上面生成的图清晰简洁,我们可以轻松地比较各个分布。除此之外,箱线图是根据分类属性中的不同值有效描述数值数据组的另一种方法。箱线图是了解数据中的四分位值以及潜在异常值的好方法。
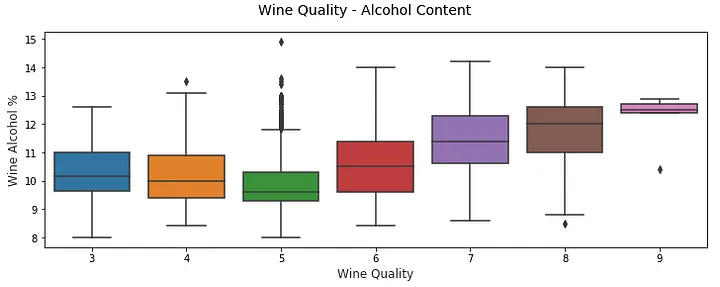
f, (ax) = plt.subplots(1, 1, figsize=(12, 4)) f.suptitle('Wine Quality - Alcohol Content' , fontsize =14) sns.boxplot(x ="quality" , y ="alcohol" , data =wines, ax =ax) ax.set_xlabel("Wine Quality" ,size = 12,alpha =0.8) ax.set_ylabel("Wine Alcohol %" ,size = 12,alpha =0.8)
另一种类似的可视化是小提琴图,这是使用核密度图(描绘不同值下数据的概率密度)可视化分组数值数据的另一种有效方法。
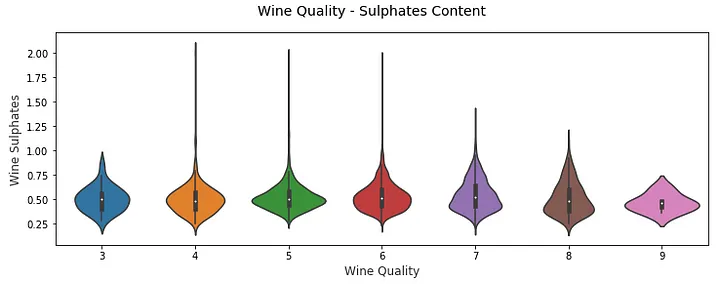
f, (ax) = plt.subplots(1, 1, figsize=(12, 4)) f.suptitle('Wine Quality - Sulphates Content' , fontsize =14) sns.violinplot(x ="quality" , y ="sulphates" , data =wines, ax =ax) ax.set_xlabel("Wine Quality" ,size = 12,alpha =0.8) ax.set_ylabel("Wine Sulphates" ,size = 12,alpha =0.8)
quality您可以清楚地看到上面不同葡萄酒类别的葡萄酒密度图sulphate。
将数据可视化到二维非常简单,但随着维度(属性)数量开始增加,变得越来越复杂。原因是我们受到显示媒介和环境的二维约束。
对于三维数据,我们可以通过在图表中采用z 轴或利用子图和面来引入虚假的深度概念。
然而,对于高于三维的数据,将其可视化变得更加困难。超越三维的最佳方法是使用绘图面、颜色、形状、大小、深度等。您还可以通过为其他属性随时间变化绘制动画图来使用时间作为维度(考虑时间是数据中的维度)。看看Hans Roslin 的精彩演讲,了解同样的想法!
三维 (3-D) 可视化数据
考虑数据中的三个属性或维度,我们可以通过考虑成对散点图并引入颜色 或色调的概念来分离分类维度中的值,从而将它们可视化。
cols = ['density' , 'residual sugar' , 'total sulfur dioxide' , 'fixed acidity' , 'wine_type' ] pp = sns.pairplot(wines[cols], hue ='wine_type' , size =1.8, aspect =1.8, palette={"red" : "#FF9999" , "white" : "#FFE888" }, plot_kws =dict(edgecolor="black", linewidth =0.5)) fig = pp.fig fig.subplots_adjust(top =0.93, wspace =0.3) t = fig.suptitle('Wine Attributes Pairwise Plots' , fontsize =14)
上图使您能够检查相关性和模式,并对葡萄酒组进行比较。我们可以清楚地看到total sulfur dioxide,与红葡萄酒相比,白葡萄酒residual sugar的含量更高。
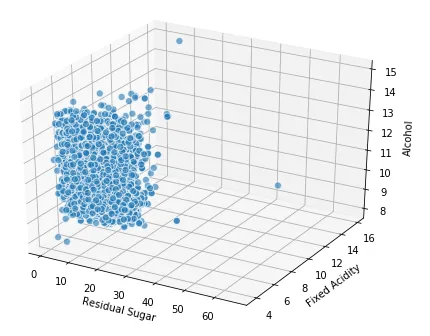
让我们看看可视化三个连续数字属性的策略。一种方法是将两个维度表示为常规长度 (x轴)和宽度(y轴),并采用深度(z轴)的概念作为第三个维度。
fig = plt.figure(figsize=(8, 6)) ax = fig.add_subplot(111, projection ='3d' ) xs = wines['residual sugar' ] ys = wines['fixed acidity' ] zs = wines['alcohol' ] ax.scatter(xs, ys, zs, s =50, alpha =0.6, edgecolors ='w' ) ax.set_xlabel('Residual Sugar' ) ax.set_ylabel('Fixed Acidity' ) ax.set_zlabel('Alcohol' )
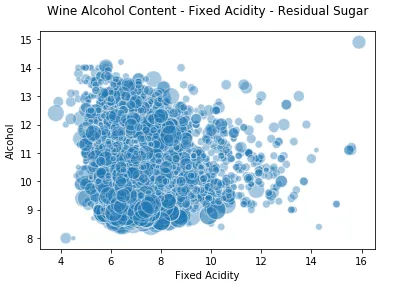
我们仍然可以利用常规的二维轴,并引入尺寸的概念作为第三维(本质上是气泡图),其中点的大小表示第三维的数量。
plt.scatter(wines['fixed acidity' ], wines['alcohol' ], s =wines['residual sugar' ]*25 , alpha =0.4, edgecolors ='w' ) plt.xlabel('Fixed Acidity' ) plt.ylabel('Alcohol' ) plt.title('Wine Alcohol Content - Fixed Acidity - Residual Sugar' ,y =1.05)
因此,您可以看到上面的图表不是传统的散点图,而是更多的气泡图,其点大小(气泡)根据 的数量而变化residual sugar。当然,您并不总是会在数据中找到明确的模式,就像在本例中一样,我们看到其他两个维度的大小不同。为了可视化三个离散的分类属性,虽然我们可以使用传统的条形图,但我们可以利用色调以及面或子图的概念来支持额外的第三个维度。该seaborn 框架帮助我们将代码保持在最低限度并有效地绘制出来。
fc = sns.factorplot(x ="quality" , hue ="wine_type" , col ="quality_label" , data =wines, kind ="count" , palette={"red" : "#FF9999" , "white" : "#FFE888" })
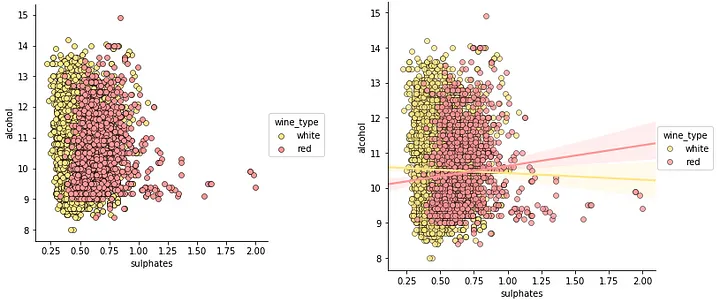
上图清楚地显示了与每个维度相关的频率,您可以看到这对于理解相关见解是多么容易和有效。考虑到三个混合属性的可视化,我们可以使用色调的概念来分隔类别属性之一中的组,同时使用散点图等传统可视化来可视化数字属性的二维。
jp = sns.pairplot(wines, x_vars=["sulphates" ], y_vars=["alcohol" ], size =4.5, hue ="wine_type" , palette={"red" : "#FF9999" , "white" : "#FFE888" }, plot_kws =dict(edgecolor="k", linewidth =0.5)) lp = sns.lmplot(x ='sulphates' , y ='alcohol' , hue ='wine_type' , palette={"red" : "#FF9999" , "white" : "#FFE888" }, data =wines, fit_reg =True , legend =True , scatter_kws =dict(edgecolor="k", linewidth =0.5))
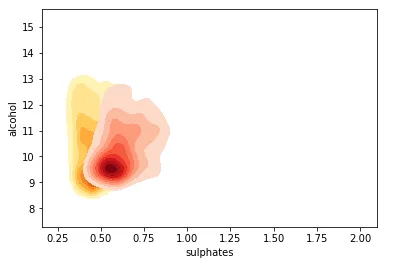
因此,色调是类别或组的良好分隔符,虽然如上所述没有相关性或相关性非常弱,但我们仍然可以从这些图中了解到,与白葡萄酒相比,红葡萄酒的相关性sulphates 略高。您还可以使用核密度图来代替散点图来了解三个维度的数据。
ax = sns.kdeplot(white_wine['sulphates' ], white_wine['alcohol' ], cmap ="YlOrBr" , shade =True , shade_lowest =False ) ax = sns.kdeplot(red_wine['sulphates' ], red_wine['alcohol' ], cmap ="Reds" , shade =True , shade_lowest =False )
与白葡萄酒相比,红葡萄酒样品中的含量是相当明显且符合预期的。您还可以根据色调强度查看密度浓度。 如果我们在三个维度中处理多个分类属性,我们可以使用色调和其中一个常规轴来可视化数据,并使用箱线图或小提琴图等可视化来可视化不同组的数据。
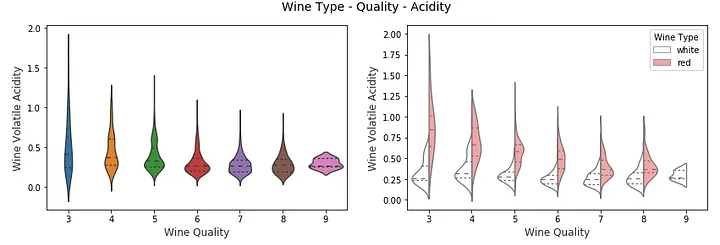
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 4)) f.suptitle('Wine Type - Quality - Acidity' , fontsize =14) sns.violinplot(x ="quality" , y ="volatile acidity" , data =wines, inner ="quart" , linewidth =1.3,ax=ax1) ax1.set_xlabel("Wine Quality" ,size = 12,alpha =0.8) ax1.set_ylabel("Wine Volatile Acidity" ,size = 12,alpha =0.8) sns.violinplot(x ="quality" , y ="volatile acidity" , hue ="wine_type" , data =wines, split =True , inner ="quart" , linewidth =1.3, palette={"red" : "#FF9999" , "white" : "white" }, ax =ax2) ax2.set_xlabel("Wine Quality" ,size = 12,alpha =0.8) ax2.set_ylabel("Wine Volatile Acidity" ,size = 12,alpha =0.8) l = plt.legend(loc ='upper right' , title ='Wine Type' )
在上图中,我们可以看到,在右侧图的 3D 可视化中,我们quality 在 x 轴上表示葡萄酒,并将其wine_type表示为色调。我们可以清楚地看到一些有趣的见解,例如红葡萄酒volatile acidity 的含量高于白葡萄酒。 您还可以考虑使用箱线图以类似的方式表示具有多个分类变量的混合属性。
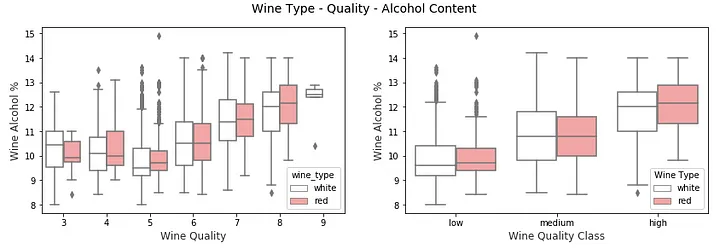
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 4)) f.suptitle('Wine Type - Quality - Alcohol Content' , fontsize =14) sns.boxplot(x ="quality" , y ="alcohol" , hue ="wine_type" , data =wines, palette={"red" : "#FF9999" , "white" : "white" }, ax =ax1) ax1.set_xlabel("Wine Quality" ,size = 12,alpha =0.8) ax1.set_ylabel("Wine Alcohol %" ,size = 12,alpha =0.8) sns.boxplot(x ="quality_label" , y ="alcohol" , hue ="wine_type" , data =wines, palette={"red" : "#FF9999" , "white" : "white" }, ax =ax2) ax2.set_xlabel("Wine Quality Class" ,size = 12,alpha =0.8) ax2.set_ylabel("Wine Alcohol %" ,size = 12,alpha =0.8) l = plt.legend(loc ='best' , title ='Wine Type' )
我们可以看到,无论是对于quality 还是quality_label 属性,葡萄酒的alcohol 含量随着质量的提高而增加。此外,根据质量等级,与白葡萄酒相比,红葡萄酒的中值含量往往略高。然而,如果我们检查质量评级,我们可以看到,对于评级较低的葡萄酒(3 和 4),白葡萄酒的中值含量高于红葡萄酒样品。除此之外,与白葡萄酒相比,红葡萄酒的中位含量似乎略高。
在四个维度 (4-D) 中可视化数据
根据我们之前的讨论,我们利用图表的各个组件可视化多个维度。以四个维度可视化数据的一种方法是在散点图等传统绘图中使用深度和色调作为特定数据维度。
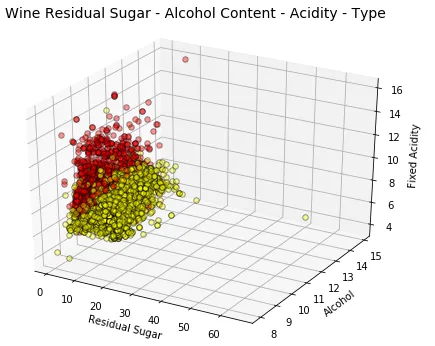
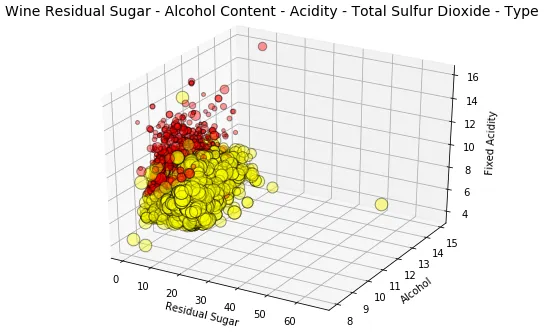
fig = plt.figure(figsize=(8, 6)) t = fig.suptitle('Wine Residual Sugar - Alcohol Content - Acidity - Type' , fontsize =14) ax = fig.add_subplot(111, projection ='3d' ) xs = list(wines['residual sugar' ]) ys = list(wines['alcohol' ]) zs = list(wines['fixed acidity' ]) data_points = [(x, y, z) for x, y, z in zip(xs, ys, zs)] colors = ['red' if wt == 'red' else 'yellow' for wt in list(wines['wine_type' ])] for data, color in zip(data_points, colors): x, y, z = data ax.scatter(x, y, z, alpha =0.4, c =color, edgecolors ='none' , s =30) ax.set_xlabel('Residual Sugar' ) ax.set_ylabel('Alcohol' ) ax.set_zlabel('Fixed Acidity' )
该 wine_type 属性由色调表示,从上图可以明显看出。此外,虽然由于绘图的复杂性,解释这些可视化开始变得困难,但您仍然可以收集见解,例如红葡萄酒fixed acidity的较高和白葡萄酒的较高。当然,如果和之间存在某种关联,我们可能会看到逐渐增加或减少的数据点平面显示出某种趋势。
另一种策略是保留二维图,但使用色调和数据点大小作为数据维度。通常,这将是一个类似于我们之前想象的气泡图。
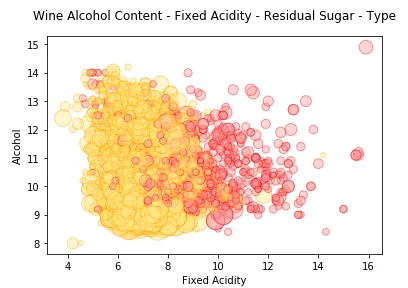
size = wines['residual sugar' ]*25 fill_colors = ['#FF9999' if wt =='red' else '#FFE888' for wt in list(wines['wine_type' ])] edge_colors = ['red' if wt =='red' else 'orange' for wt in list(wines['wine_type' ])] plt.scatter(wines['fixed acidity' ], wines['alcohol' ], s =size, alpha =0.4, color =fill_colors, edgecolors =edge_colors) plt.xlabel('Fixed Acidity' ) plt.ylabel('Alcohol' ) plt.title('Wine Alcohol Content - Fixed Acidity - Residual Sugar - Type' ,y =1.05)
我们用色调来表示 wine_type ,用数据点大小来表示residual sugar。我们确实看到了与上一张图表中观察到的类似模式,白葡萄酒的气泡尺寸较大,通常表明白葡萄酒residual sugar的值高于红葡萄酒。 如果我们要表示两个以上的分类属性,我们可以重用利用色调和面的概念来描述这些属性,并使用散点图等常规图来表示数字属性。让我们看几个例子。
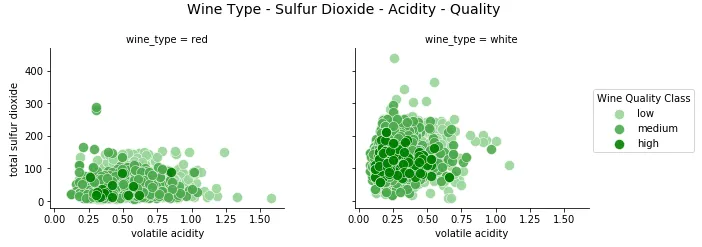
g = sns.FacetGrid(wines, col ="wine_type" , hue ='quality_label' , col_order=['red' , 'white' ], hue_order=['low' , 'medium' , 'high' ], aspect =1.2, size =3.5, palette =sns.light_palette('navy', 4)[1:]) g.map(plt.scatter, "volatile acidity" , "alcohol" , alpha =0.9, edgecolor ='white' , linewidth =0.5, s =100) fig = g.fig fig.subplots_adjust(top =0.8, wspace =0.3) fig.suptitle('Wine Type - Alcohol - Quality - Acidity' , fontsize =14) l = g.add_legend(title ='Wine Quality Class' )
我们可以轻松发现多种模式,这一事实验证了这种可视化的有效性。白葡萄酒volatile acidity的酸度较低,优质葡萄酒的酸度也较低。同样根据白葡萄酒样品,高质量的葡萄酒具有较高的水平,而低质量的葡萄酒具有最低的水平!
五维 (5-D) 可视化数据
再次遵循与上一节类似的策略,为了在五个维度上可视化数据,我们利用各种绘图组件。除了表示其他两个维度的常规轴之外,让我们使用深度、色调和大小来表示三个数据维度。由于我们使用大小的概念,因此我们基本上将绘制三维气泡图。
fig = plt.figure(figsize=(8, 6)) ax = fig.add_subplot(111, projection ='3d' ) t = fig.suptitle('Wine Residual Sugar - Alcohol Content - Acidity - Total Sulfur Dioxide - Type' , fontsize =14) xs = list(wines['residual sugar' ]) ys = list(wines['alcohol' ]) zs = list(wines['fixed acidity' ]) data_points = [(x, y, z) for x, y, z in zip(xs, ys, zs)] ss = list(wines['total sulfur dioxide' ]) colors = ['red' if wt == 'red' else 'yellow' for wt in list(wines['wine_type' ])] for data, color, size in zip(data_points, colors, ss): x, y, z = data ax.scatter(x, y, z, alpha =0.4, c =color, edgecolors ='none' , s =size) ax.set_xlabel('Residual Sugar' ) ax.set_ylabel('Alcohol' ) ax.set_zlabel('Fixed Acidity' )
该图表描绘了我们在上一节中讨论的相同模式和见解。然而,我们也可以看到,根据所代表的点大小total sulfur dioxide,白葡萄酒的total sulfur dioxide含量高于红葡萄酒。
除了深度之外,我们还可以使用构面和色调来表示这五个数据维度中的多个分类属性。表示大小的属性之一可以是数字(连续)甚至是分类(但我们可能需要用数据点大小的数字来表示)。虽然由于缺乏分类属性,我们没有在这里描述这一点,但请随意在您自己的数据集上尝试一下。
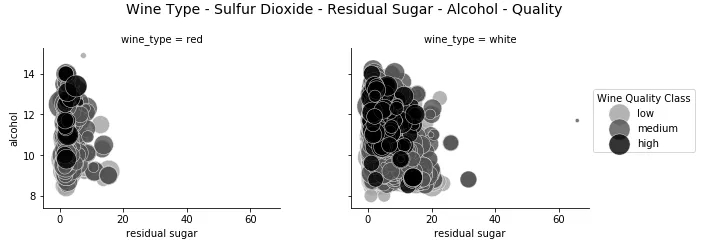
g = sns.FacetGrid(wines, col ="wine_type" , hue ='quality_label' , col_order=['red' , 'white' ], hue_order=['low' , 'medium' , 'high' ], aspect =1.2, size =3.5, palette =sns.light_palette('black', 4)[1:]) g.map(plt.scatter, "residual sugar" , "alcohol" , alpha =0.8, edgecolor ='white' , linewidth =0.5, s =wines['total sulfur dioxide' ]*2 ) fig = g.fig fig.subplots_adjust(top =0.8, wspace =0.3) fig.suptitle('Wine Type - Sulfur Dioxide - Residual Sugar - Alcohol - Quality' , fontsize =14) l = g.add_legend(title ='Wine Quality Class' )
这基本上是可视化我们之前绘制的五个维度的同一图的另一种方法。虽然在查看我们之前绘制的图时,深度的附加维度可能会让许多人感到困惑,但由于面的优势,该图仍然有效地保留在二维平面上,因此通常更有效且易于解释。
六维 (6-D) 可视化数据
现在我们已经玩得很开心了(我希望如此!),让我们在可视化中添加另一个数据维度。除了常规的两个轴之外,我们还将利用深度、色调、大小和形状来描述所有六个数据维度。
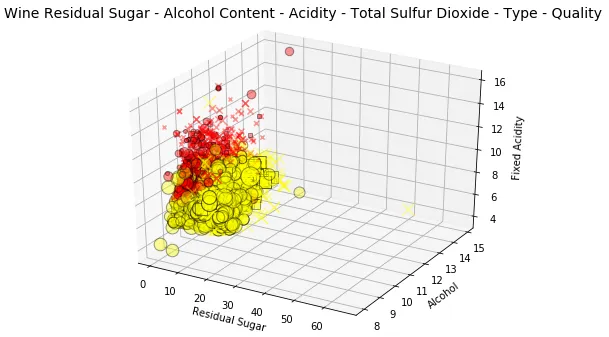
fig = plt.figure(figsize=(8, 6)) t = fig.suptitle('Wine Residual Sugar - Alcohol Content - Acidity - Total Sulfur Dioxide - Type - Quality' , fontsize =14) ax = fig.add_subplot(111, projection ='3d' ) xs = list(wines['residual sugar' ]) ys = list(wines['alcohol' ]) zs = list(wines['fixed acidity' ]) data_points = [(x, y, z) for x, y, z in zip(xs, ys, zs)] ss = list(wines['total sulfur dioxide' ]) colors = ['red' if wt == 'red' else 'yellow' for wt in list(wines['wine_type' ])] markers = [',' if q == 'high' else 'x' if q == 'medium' else 'o' for q in list(wines['quality_label' ])] for data, color, size, mark in zip(data_points, colors, ss, markers): x, y, z = data ax.scatter(x, y, z, alpha =0.4, c =color, edgecolors ='none' , s =size, marker =mark) ax.set_xlabel('Residual Sugar' ) ax.set_ylabel('Alcohol' ) ax.set_zlabel('Fixed Acidity' )
哇,一个情节中有六个维度!我们用形状quality_label来描述葡萄酒,高品质(方形像素)、中品质(X 标记)和低品质(圆圈)的葡萄酒。由色调表示,由深度和数据点大小表示内容。
解释这一点可能看起来有点费力,但在尝试了解正在发生的情况时一次考虑几个组件。
考虑到形状和y 轴,与低品质葡萄酒相比,我们拥有更高水平的高品质和中品质葡萄酒。alcohol
考虑到颜色和大小,与红葡萄酒相比,白葡萄酒total sulfur dioxide的含量更高。
考虑到深度和色调,与红葡萄酒相比,我们的白葡萄酒含量较低。fixed acidity
考虑到色调和x 轴,与白葡萄酒相比,我们的红葡萄酒的含量较低。residual sugar
考虑到色调和形状,与红葡萄酒相比,白葡萄酒似乎具有更高品质的葡萄酒(可能是由于白葡萄酒的样本量较大)。
我们还可以通过删除深度组件来构建 6 维可视化,并使用构面代替分类属性。
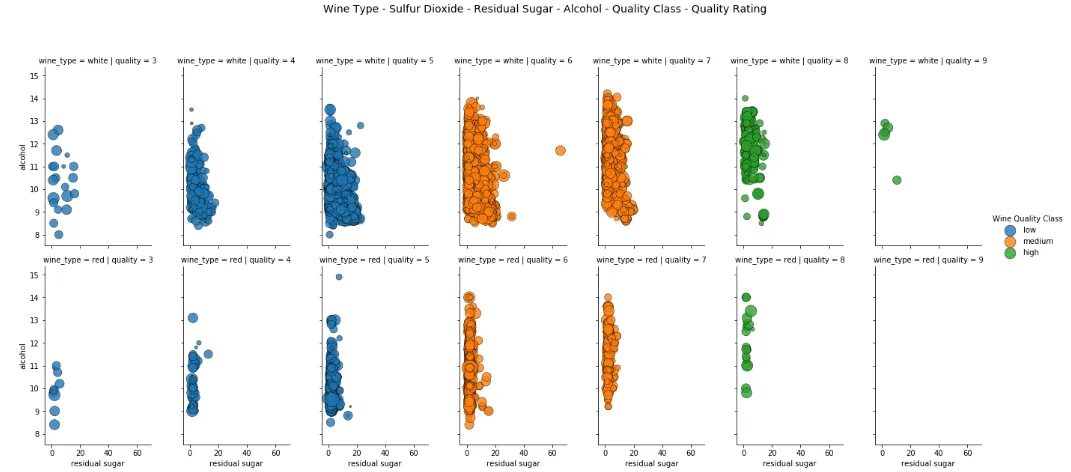
g = sns.FacetGrid(wines, row ='wine_type' , col ="quality" , hue ='quality_label' , size =4) g.map(plt.scatter, "residual sugar" , "alcohol" , alpha =0.5, edgecolor ='k' , linewidth =0.5, s =wines['total sulfur dioxide' ]*2 ) fig = g.fig fig.set_size_inches(18, 8) fig.subplots_adjust(top =0.85, wspace =0.3) fig.suptitle('Wine Type - Sulfur Dioxide - Residual Sugar - Alcohol - Quality Class - Quality Rating' , fontsize =14) l = g.add_legend(title ='Wine Quality Class' )
因此,在这种情况下,我们利用构面和色调来表示三个分类属性,并利用两个规则轴和大小来表示 6 维数据可视化的三个数值属性。
结论
数据可视化是一门艺术,也是一门科学。如果您正在阅读本文,我真诚地赞扬您为阅读这篇内容广泛的文章所做的努力。目的不是为了记住任何东西,也不是为了给出一组固定的数据可视化规则。这里的主要目标是理解和学习一些有效的数据可视化策略,特别是当维度数量开始增加时。我鼓励您将来利用这些片段来可视化您自己的数据集。
参考
[1] 多维数据有效可视化的艺术